pmeerw's blog
pmeerw's blog
pmeerw's blog
pmeerw's blog
We have a significant workload (> 50k CPU hours per year) on AWS EC2 instances running a Windows program. Since Linux instances are cheaper and easier to maintain (think Docker), we tried to get that Windows application running using Wine. A native Linux port is unfortunately not feasible, since the application depends on some closed-source libraries.
Initial benchmarks were not encouraging:
| Platform | Runtime |
|---|---|
| Windows 11 | 479 s |
| Linux 6.12 | 2636 s |
Wine offers nice logging/tracing abilities by setting the environment variable WINEDEBUG=+relay,+heap.
This revealed far too many calls to heap allocation functions. Since the application is statically linked against the C runtime,
Wine's heap allocation function may be less optimized than the original Windows function or require more overhead.
Also perf top points to Wine's heap_allocation_block function.
mimalloc is a general purpose memory allocator with excellent performance.
For statically-linked programs, it is possible to override the global C++ new and delete operators by just
#including mimalloc-new-delete.h
in one source file.
Benchmarks for the same program/workload as above, statically linked with mimalloc:
| Platform | Allocator | Runtime | Peak Memory |
|---|---|---|---|
| Windows 11 | default | 479 s | 12.6 GB |
| Windows 11 | mimalloc v3.0.3 | 438 s | 12.2 GB |
| Windows 11 | mimalloc v2.2.3 | 440 s | 12.9 GB |
| Linux 6.12 | default | 2636 s | 14.3 GB |
| Linux 6.12 | mimalloc v3.0.3 | crash | N/A |
| Linux 6.12 | mimalloc v2.2.3 | 435 s | 12.4 GB |
The crash on Linux with mimalloc v3.0.3 is probably related to issue #1087 and due to the new page-map feature having trouble with low addresses of memory allocations (which Wine provides) -- looking forward to a fix!
posted at: 12:46 | path: /programming | permanent link
... from the command-line.
export STEAM_COMPAT_DATA_PATH=/data/SteamLibrary/steamapps/compatdata/123456 export STEAM_COMPAT_CLIENT_INSTALL_PATH=/home/user/.steam/debian-installation python3 "/data/SteamLibrary/steamapps/common/Proton - Experimental/proton" waitforexitandrun some.exe
posted at: 09:52 | path: /programming | permanent link
A signed Windows executable allows windows to display the publisher name in the UAC dialog, except sometimes it doesn't work. Windows uses Authenticode to verify the integrity of a PE32 executable and provide authentication via code signing.
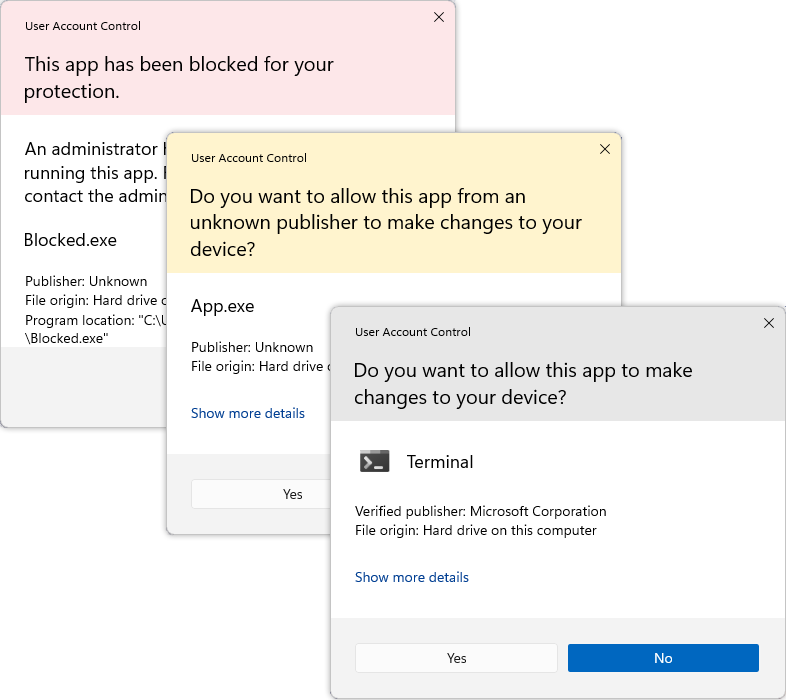
One way to learn more what UAC does w.r.t. crypto is to enable CAPI2 diagnostics , i.e. event logging.
Things to remember: the entire certificate chain up to but not including the root CA's certificate should be in the executable, i.e. all intermediate certificate. When certificate are missing, they might be retrieved by Certificate Authority Information Access (AIA), specified in RFC5280 via some HTTP URLs given in the certificates.
Different applications implement different verification policies: caching of certifiates, revocation list checks, etc. It's know clear what checks Windows, or the UAC dialog, or other application do to check the authenticity of an executable.
Tooling is difficult: again, it's not clear what the verification policy is. For example, Microsoft's signtool does not complain about missing intermediate certificates.
Looking for some more mystery to research: Try page hashes!
posted at: 00:45 | path: /programming | permanent link
C++ code compiles with release build, fails with debug build (/D_DEBUG); MSVC obviously
Expectation: define _DEBUG (or switching between release and debug build) doesn’t change whether code is accepted; apparently Mircosoft has a different view...
// source code, x.cpp
#include <cstdio>
#include <string>
static constexpr std::string s = “asdf”;
int main() {
printf(“%s\n”, s.c_str());
}
Compile with debug:
cl /std:c++20 /D_DEBUG x.cpp Microsoft ® C/C++ Optimizing Compiler Version 19.39.33520 for x64 Copyright © Microsoft Corporation. All rights reserved. x.cpp x.cpp(4): error C2131: expression did not evaluate to a constant x.cpp(4): note: (sub-)object points to memory which was heap allocated during constant evaluationCompile as release:
cl /std:c++20 x.cpp Microsoft ® C/C++ Optimizing Compiler Version 19.39.33520 for x64 Copyright © Microsoft Corporation. All rights reserved. x.cpp Microsoft ® Incremental Linker Version 14.39.33520.0 Copyright © Microsoft Corporation. All rights reserved. /out:x.exe x.obj
Bonus: when the initializer string “asdf” is longer, e.g. “aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaasdf” also the release build fails (which is OK)
There's actually a very good and detailed technical explanation.
posted at: 10:00 | path: /programming | permanent link
Configuring editors to not append a newline at the end (before the end-of-file, EOF):
nano -L or put set nonewlines in ~/.nanorc
gsettings set org.gnome.gedit.preferences.editor ensure-trailing-newline false
(see here also)
posted at: 23:13 | path: /programming | permanent link