pmeerw's blog
pmeerw's blog
pmeerw's blog
pmeerw's blog
Mar 2010
Eigen is a C++ template library for linear algebra: vectors, matrices, and related algorithms. The GNU Scientific Library (GSL) is a numerical C library which builds on BLAS for more complicated matrix operations.
Compiled with:
g++ -static -O3 -Wall -I/tmp/eigen -msse3 -ffast-math -mfpmath=sse -o mm
mm.cpp -lgsl /usr/lib/sse2/libcblas.a /usr/lib/sse2/libatlas.a
Note: several other ways to link GSL with BLAS are possible, but all were
slower (Ubuntu 8.10, 32bit).
eigen 0.380
GSL 0.780
#include <cstdlib> #include <cstdio> #include <ctime> #define EIGEN2_SUPPORT #include "Eigen/Core" USING_PART_OF_NAMESPACE_EIGEN #include#include int main() { clock_t t; MatrixXf ea; MatrixXf eb; ea = MatrixXf::Random(18, 18); eb = MatrixXf::Random(18, 256); t = clock(); for (int i = 0; i < 10000; i++) MatrixXf er = ea * eb; printf("eigen %.3f\n", (clock() - t) / (float) CLOCKS_PER_SEC); gsl_matrix *ga = gsl_matrix_alloc(18, 18); gsl_matrix *gb = gsl_matrix_alloc(18, 256); gsl_matrix *gr = gsl_matrix_alloc(18, 256); t = clock(); for (int i = 0; i < 10000; i++) gsl_blas_dgemm(CblasNoTrans, CblasNoTrans, 1.0, ga, gb, 0.0, gr); printf("GSL %.3f\n", (clock() - t) / (float) CLOCKS_PER_SEC); gsl_matrix_free(ga); gsl_matrix_free(gb); gsl_matrix_free(gr); return EXIT_SUCCESS; }
posted at: 16:32 | path: /programming | permanent link
Trying different compilers for double precision math...
icc -fast -march=core2 (icc 11.1.069, 32bit)
g++-4.2 -O2 -ffast-math -msse3 (Ubuntu 8.10, 32bit)
g++-4.2 -O2 -ffast-math -msse3 -mfpmath=sse (Ubuntu 8.10, 32bit)
g++-4.4 -O3 -ffast-math -msse3 -mfpmath=sse -march=core2 (gcc 4.4 early experimental, 32bit)
g++-4.4 -O3 -ffast-math -msse3 -mfpmath=sse -march=core2 (Ubuntu 9.10, 64bit)
log, exp, pow, gcc is
doing better on erfc, erf, gamma
-- the accuracy might be different though.
For comparison, the 64bit machine is a bit faster (3 GHz) than the 32bit
one (2.67 GHz).
The Intel compiler is always using SSE instructions and has reasonable
good SSE implementations for log, exp,
pow; the GNU compiler struggles with FPU instructions and
does not have double-precision SSE code, some operations get slower with
SSE, e.g. floor, tan, log.
It is hard to get good overall performance with gcc for 32bit,
64bit fares better.
To speed up log and exp, one can use approximate
math functions (at single precision). Shigeo MITSUNARI offers fmath which
implements log and exp in SSE with table
lookups. It also can benefit from the Xbyak JIT
compiler.
José Fonseca has a blog entry Fast SSE2 pow: tables or polynomials? which also looks interesting.
| icc | gcc-4.2 | gcc-4.2 | (gcc-4.4) | gcc-4.4 | |
| float->double | 150 | 120 | 120 | 110 | 70 |
| double->float | 110 | 90 | 90 | 90 | 100 |
| erf | 5020 | 1960 | 1990 | 1960 | 1080 |
| erfc | 9600 | 2310 | 2220 | 2220 | 1270 |
| gamma | 12040 | 6340 | 6340 | 6340 | 6570 |
| tgamma | 9050 | 12660 | 12570 | 12890 | 9920 |
| log | 1900 | 2340 | 4390 | 4430 | 4440 |
| fmath::log | 560 | 1170 | 490 | 590 | 450 |
| exp | 1290 | 5290 | 6280 | 6380 | 2870 |
| fmath::exp | 640 | 600 | 650 | 660 | 620 |
| pow | 3660 | 11980 | 11820 | 11680 | 9210 |
| fmath::pow | 2170 | 2720 | 1650 | 1800 | 1580 |
| sqrt | 2140 | 2550 | 2140 | 2140 | 640 |
| cos | 1660 | 3380 | 3870 | 3860 | 1690 |
| tan | 2520 | 4840 | 5930 | 5930 | 3480 |
| atan | 1600 | 5330 | 5880 | 5630 | 1660 |
| mul | 91 | 91 | 86 | 98 | 99 |
| div | 1190 | 1400 | 1170 | 1180 | 680 |
| add | 92 | 96 | 87 | 93 | 99 |
| floor | 356 | 788 | 2177 | 319 | 262 |
| fabs | 88 | 90 | 91 | 89 | 96 |
Here's the updated code using the fmath library.
#include <cmath>
#include <cstdio>
#include <ctime>
#include <cstdlib>
#include "fmath.hpp"
int main() {
volatile double a;
volatile double b = 0.8234234;
volatile double c = 1.43234;
volatile float d;
clock_t t;
const int N = 100000000;
t = clock();
for (int i=0; i < N; i++)
a = d;
printf("float -> double %.3f\n", (clock()-t) / (float)
CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
d = a;
printf("double -> float %.3f\n", (clock()-t) / (float)
CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = erf(b);
printf("erf %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = erfc(b);
printf("erfc %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = gamma(b);
printf("gamma %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = tgamma(b);
printf("tgamma %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = log(b);
printf("log %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = fmath::log(b);
printf("fmath::log %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = exp(b);
printf("exp %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = fmath::exp(b);
printf("fmath::exp %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = pow(b, c);
printf("pow %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = fmath::exp(fmath::log(b) * c);
printf("fmath::pow %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = sqrt(b);
printf("sqrt %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = cos(b);
printf("cos %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = tan(b);
printf("tan %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = atan(b);
printf("atan %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < 10*N; i++)
a = b*c;
printf("mul %.3f\n", (clock()-t) / 10 / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = b/c;
printf("div %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < 10*N; i++)
a = b+c;
printf("add %.3f\n", (clock()-t) / 10 / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < 10*N; i++)
a = floor(b);
printf("floor %.3f\n", (clock()-t) / 10 / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < 10*N; i++)
a = fabs(b);
printf("fabs %.3f\n", (clock()-t) / 10 / (float) CLOCKS_PER_SEC);
return EXIT_SUCCESS;
}
posted at: 15:34 | path: /programming | permanent link
Sometimes you really want to know... (continuation of my previous writeup)
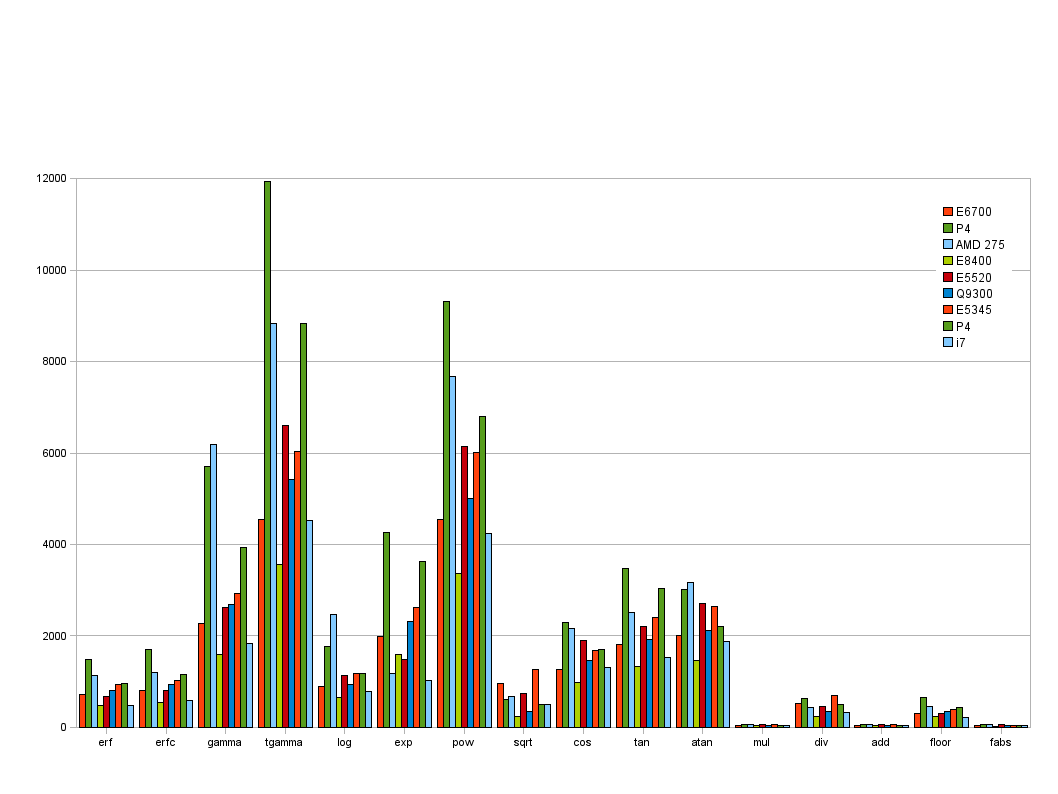
Runtime for various double-precision floating-point arithmetic operations, normalized by clock frequency, across several CPU models; P4 and Opteron suck, E8400 is consistently the fastest. Surprisingly, div and floor are quite slow, pow is dead slow.
posted at: 18:10 | path: /programming | permanent link
Sometimes one wants to know...
Results in seconds for 100000000 (1e8) operations on Intel Core2 CPU (E6700), 2.66
GHz, code (see below) was compiled with g++ -static -O2 -Wall -ffast-math -o
fptime.cpp, GCC 4.2.4
erf 1.900
erfc 2.120
gamma 6.020
tgamma 12.120
log 2.360
exp 5.290
pow 12.090
sqrt 2.550
cos 3.390
tan 4.840
atan 5.330
mul 0.103
div 1.400
add 0.105
floor 0.792
fabs 0.097
#include <cmath>
#include <cstdio>
#include <ctime>
#include <cstdlib>
using namespace std;
int main() {
volatile double a;
volatile double b = 0.8234234;
volatile double c = 1.43234;
clock_t t;
const int N = 100000000;
t = clock();
for (int i=0; i < N; i++)
a = erf(b);
printf("erf %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = erfc(b);
printf("erfc %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = gamma(b);
printf("gamma %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = tgamma(b);
printf("tgamma %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = log(b);
printf("log %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = exp(b);
printf("exp %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = pow(b, c);
printf("pow %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = sqrt(b);
printf("sqrt %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = cos(b);
printf("cos %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = tan(b);
printf("tan %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = atan(b);
printf("atan %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < 10*N; i++)
a = b*c;
printf("mul %.3f\n", (clock()-t) / 10 / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < N; i++)
a = b/c;
printf("div %.3f\n", (clock()-t) / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < 10*N; i++)
a = b+c;
printf("add %.3f\n", (clock()-t) / 10 / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < 10*N; i++)
a = floor(b);
printf("floor %.3f\n", (clock()-t) / 10 / (float) CLOCKS_PER_SEC);
t = clock();
for (int i=0; i < 10*N; i++)
a = fabs(b);
printf("fabs %.3f\n", (clock()-t) / 10 / (float) CLOCKS_PER_SEC);
return EXIT_SUCCESS;
}
posted at: 19:55 | path: /programming | permanent link
One might think that SDKs are supposed to facilitate programming, which
not the case for the NVidia OpenCL SDK. Here is how I got very
basic OpenCL code working...
Disclaimer: Linux only, using Ubuntu 8.10 Hardy
First, it is not clear what version of the graphics driver, CUDA and OpenCL SDK you are supposed to install. The latest (stable) graphics drivers do not include OpenCL.so, version 195.36.15 worked for me.
Second, what version of CUDA? cudatoolkit 3.0 worked for me, maybe you are supposed to use cudasdk 2.3? or maybe cudatoolkit 2.3?
Third, what version of OpenCL? the package is convincingly named gpucomputingsdk 2.3a, so maybe to be used with the 2.3 CUDA stuff? CUDA SDK 3.x also contains the relevant OpenCL header files, and there are no libs except for the OpenCL.so shipped with the graphics driver; good documentation is available from the khronos size.
In the end, the OpenCL samples fail to work as
// Create the OpenCL context on a GPU device cxGPUContext = clCreateContextFromType(0, CL_DEVICE_TYPE_GPU, NULL, NULL, &ciErr1);returns
-32 (CL_INVALID_PLATFORM), other samples just
crash. Turns out
that the first parameter must not be zero; specification says the
behaviour is implementation-defined if zero -- great idea to put such
code in the SDK samples. Properly calling
clGetPlatformIDs() and you are good to go!
Here is some device query code which works for me:
#include "CL/cl.h"
int main() {
cl_uint n;
cl_platform_id plat_ids[3];
cl_int ret = clGetPlatformIDs(3, plat_ids, &n);
printf("ret = %d, platforms = %d\n", ret, n);
for (cl_uint i = 0; i < n; i++) {
char buf[1024];
size_t bytes;
ret = clGetPlatformInfo(plat_ids[i], CL_PLATFORM_VERSION, sizeof(buf), buf, &bytes);
printf("ret = %d, bytes = %d, version %s\n", ret, bytes, buf);
ret = clGetPlatformInfo(plat_ids[i], CL_PLATFORM_NAME, sizeof(buf), buf, &bytes);
printf("ret = %d, bytes = %d, name %s\n", ret, bytes, buf);
}
cl_device_id dev_ids[3];
ret = clGetDeviceIDs(plat_ids[0], CL_DEVICE_TYPE_GPU, 3, dev_ids, &n);
printf("ret = %d, devices = %d\n", ret, n);
char buf[1024];
size_t bytes;
ret = clGetDeviceInfo(dev_ids[0], CL_DEVICE_AVAILABLE, sizeof(buf), buf, &bytes);
printf("ret = %d, bytes = %d, avail %d\n", ret, bytes, *(cl_bool*) &buf);
ret = clGetDeviceInfo(dev_ids[0], CL_DEVICE_GLOBAL_MEM_SIZE, sizeof(buf), buf, &bytes);
printf("ret = %d, bytes = %d, global mem %lld\n", ret, bytes, *(cl_ulong*) &buf);
ret = clGetDeviceInfo(dev_ids[0], CL_DEVICE_LOCAL_MEM_SIZE, sizeof(buf), buf, &bytes);
printf("ret = %d, bytes = %d, local mem %lld\n", ret, bytes, *(cl_ulong*) &buf);
ret = clGetDeviceInfo(dev_ids[0], CL_DEVICE_GLOBAL_MEM_CACHE_SIZE, sizeof(buf), buf, &bytes);
printf("ret = %d, bytes = %d, global mem cache %lld\n", ret, bytes, *(cl_ulong*) &buf);
ret = clGetDeviceInfo(dev_ids[0], CL_DEVICE_IMAGE_SUPPORT, sizeof(buf), buf, &bytes);
printf("ret = %d, bytes = %d, image support %d\n", ret, bytes, *(cl_bool*) &buf);
ret = clGetDeviceInfo(dev_ids[0], CL_DEVICE_IMAGE2D_MAX_HEIGHT, sizeof(buf), buf, &bytes);
printf("ret = %d, bytes = %d, image 2d max height %d\n", ret, bytes, *(size_t*) &buf);
ret = clGetDeviceInfo(dev_ids[0], CL_DEVICE_MAX_CLOCK_FREQUENCY, sizeof(buf), buf, &bytes);
printf("ret = %d, bytes = %d, clock freq %d\n", ret, bytes, *(cl_uint*) &buf);
ret = clGetDeviceInfo(dev_ids[0], CL_DEVICE_MAX_COMPUTE_UNITS, sizeof(buf), buf, &bytes);
printf("ret = %d, bytes = %d, compute units %d\n", ret, bytes, *(cl_uint*) &buf);
ret = clGetDeviceInfo(dev_ids[0], CL_DEVICE_MAX_WORK_GROUP_SIZE, sizeof(buf), buf, &bytes);
printf("ret = %d, bytes = %d, work group size %d\n", ret, bytes, *(size_t*) &buf);
ret = clGetDeviceInfo(dev_ids[0], CL_DEVICE_NAME, sizeof(buf), buf, &bytes);
printf("ret = %d, bytes = %d, name %s\n", ret, bytes, buf);
cl_context_properties props[3];
props[0] = CL_CONTEXT_PLATFORM;
props[1] = (cl_context_properties)plat_ids[0];
props[2] = 0;
cl_context ctx = clCreateContextFromType(props, CL_DEVICE_TYPE_GPU, 0, 0, &ret);
printf("ret = %d\n", ret);
return 0;
}
posted at: 12:30 | path: /rant | permanent link
Playing with valgrind's version 3.5 helgrind (thread error detector), drd (data race detector) and ptrcheck (array overrun detector) tools, I'm really impressed.
posted at: 23:09 | path: /programming | permanent link